Flow Matching for Multimodal Distributions
2School of Mathematics 3School of Statistics
University of Minnesota Twin Cities
CVPR 2026
 Paper (Coming soon)
Paper (Coming soon) Code (Coming soon)
Code (Coming soon)
Motivation
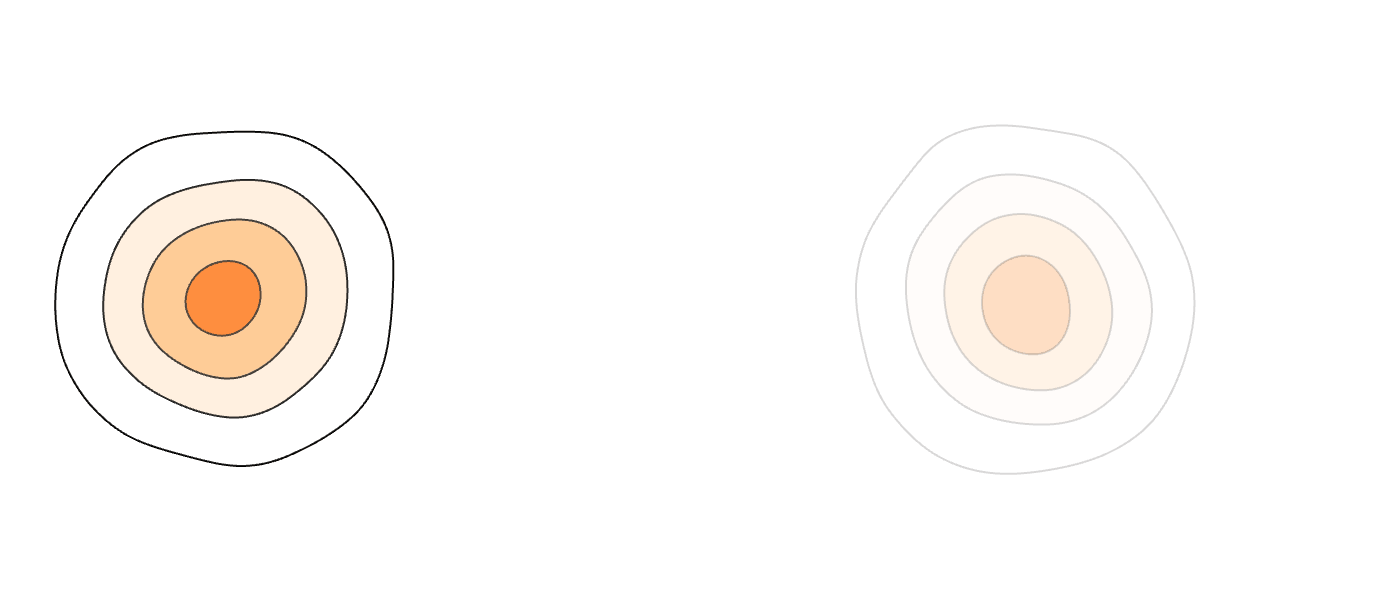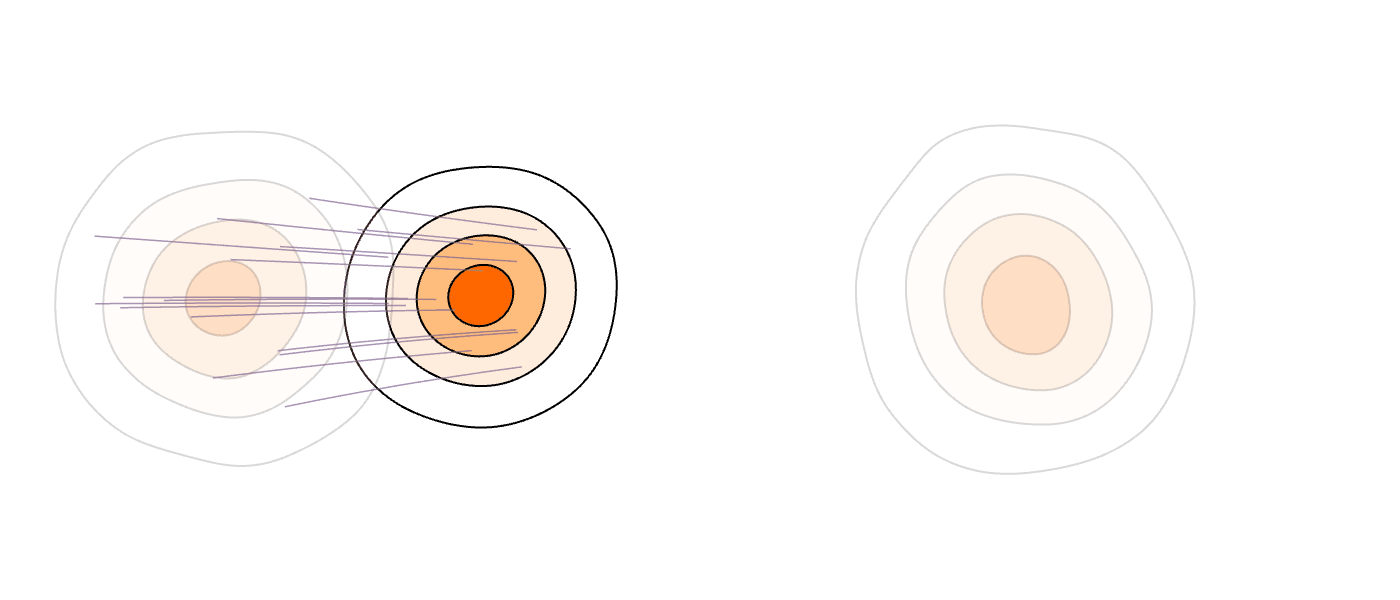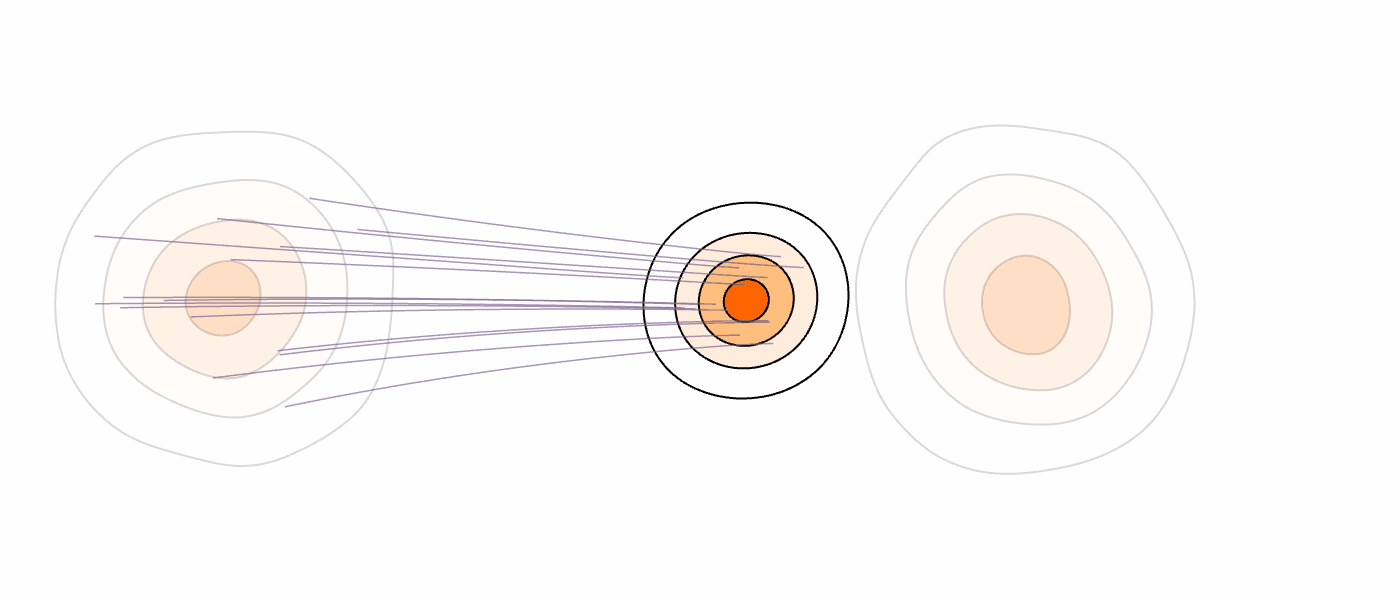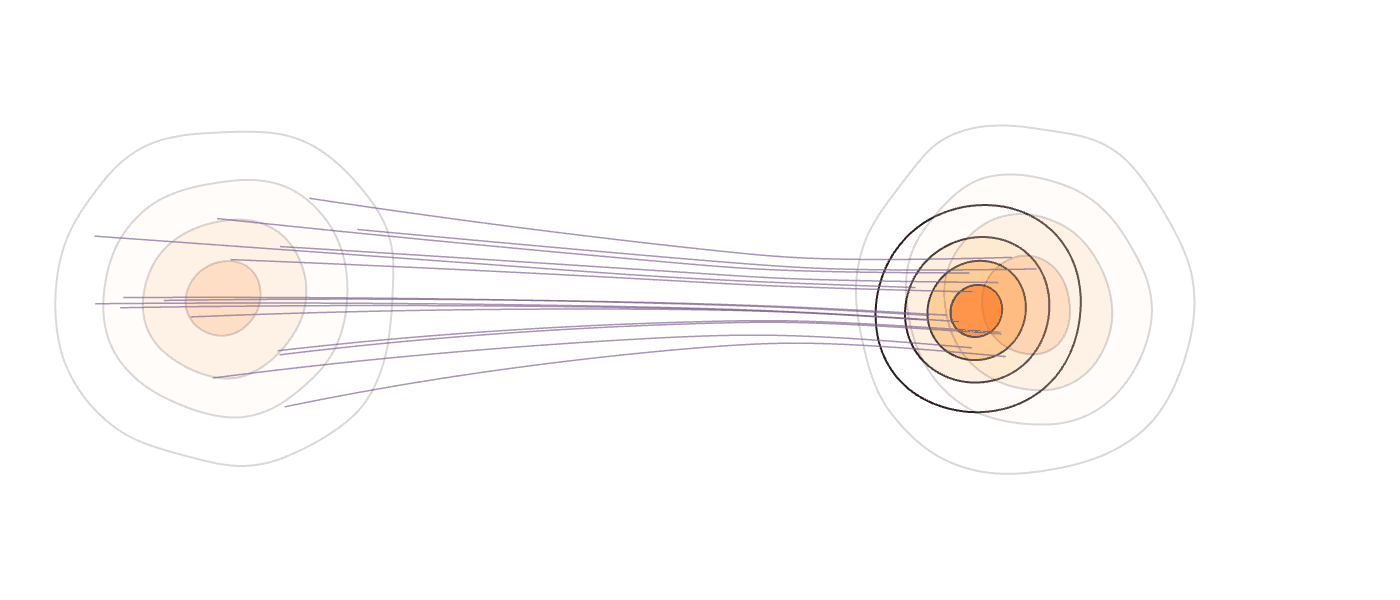
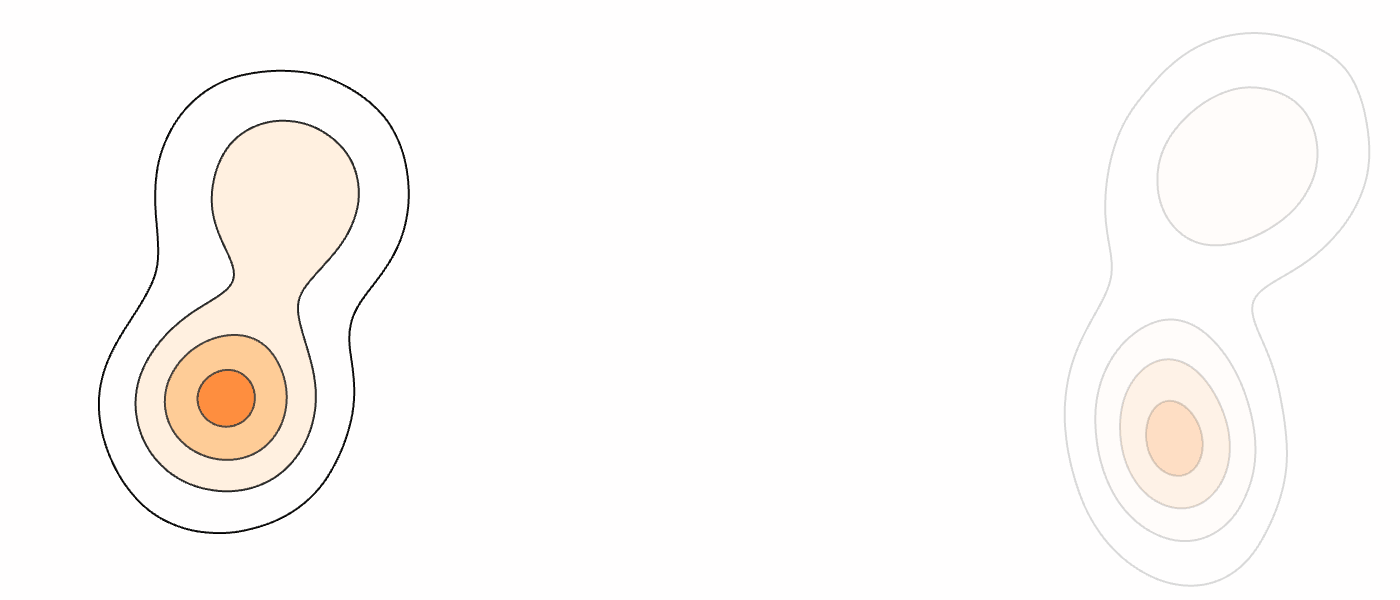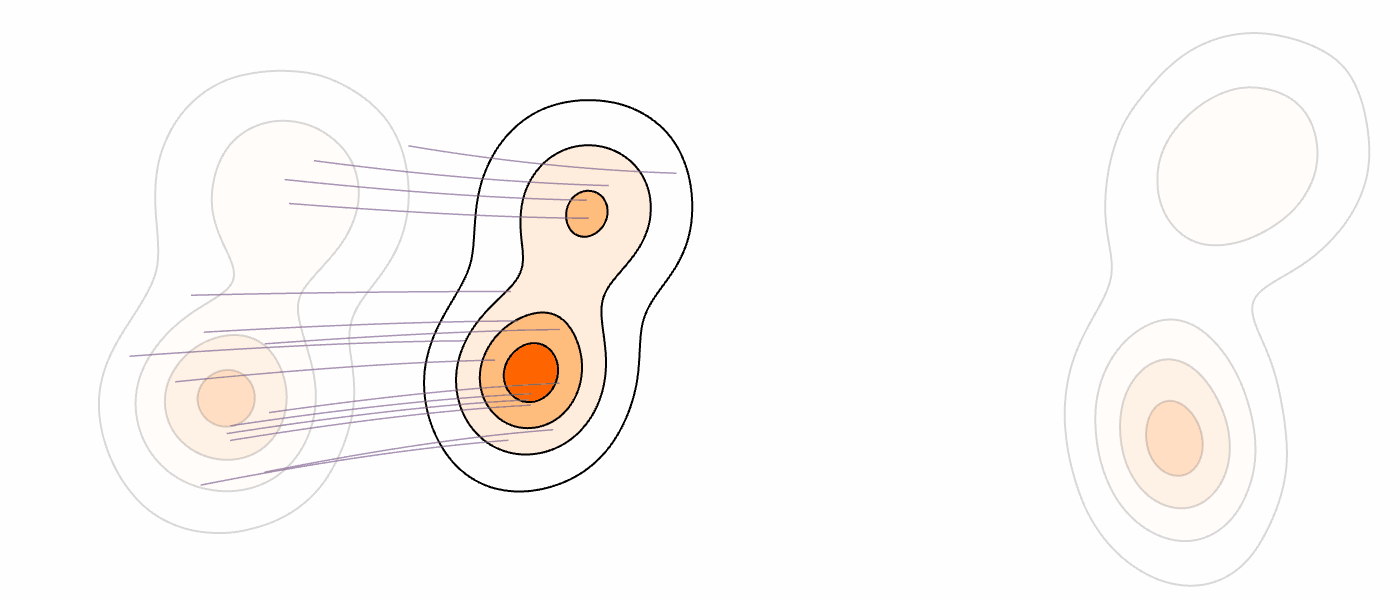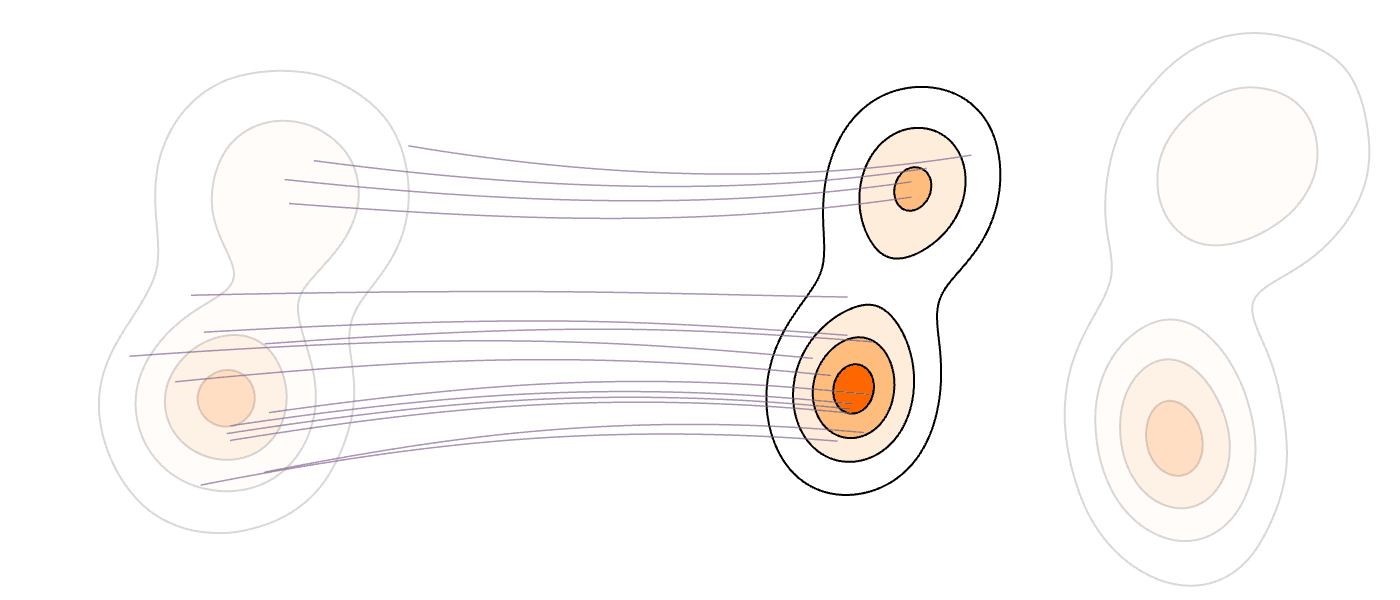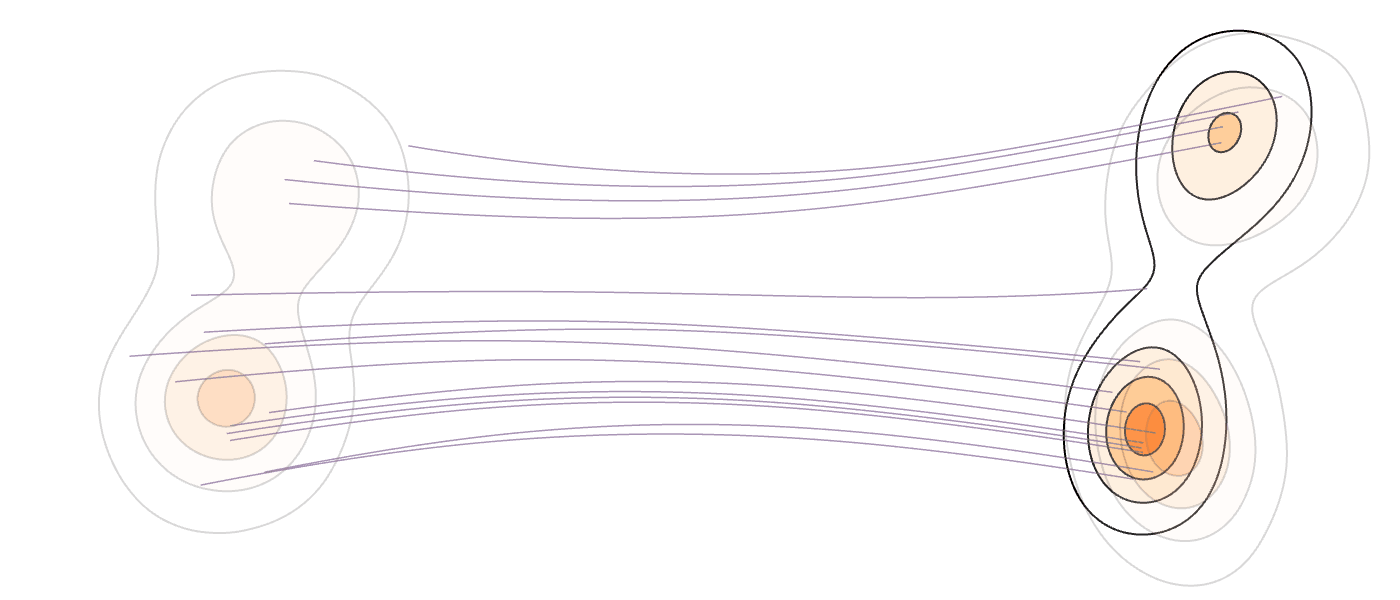

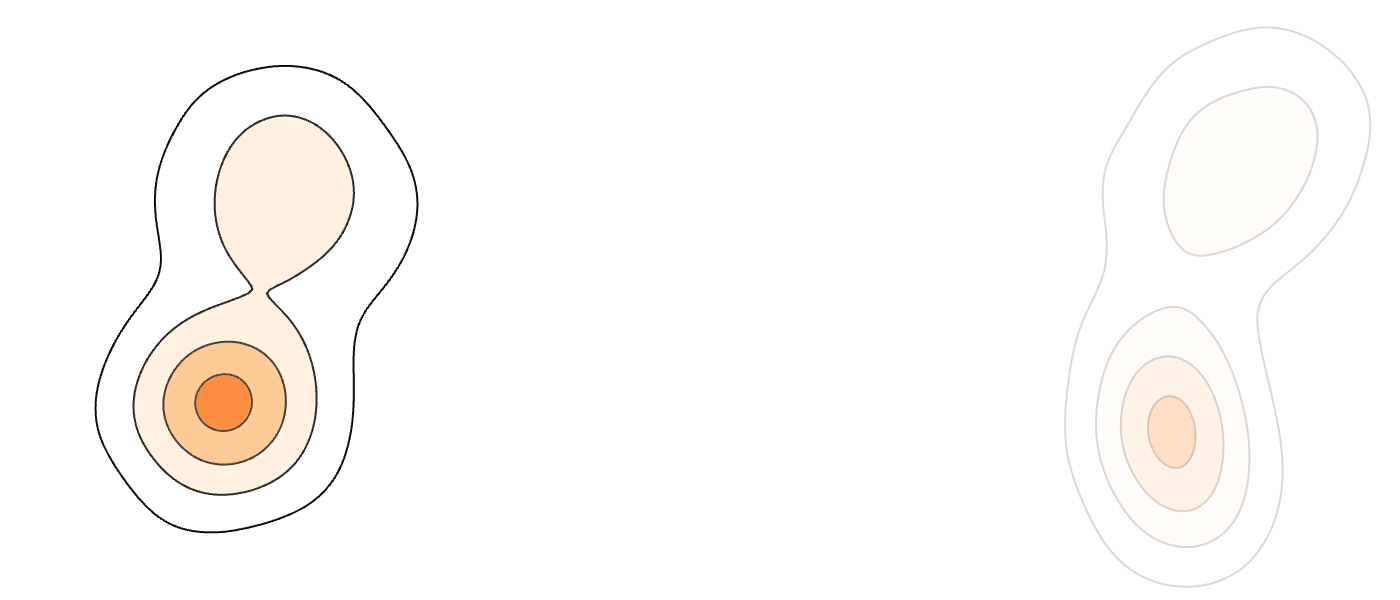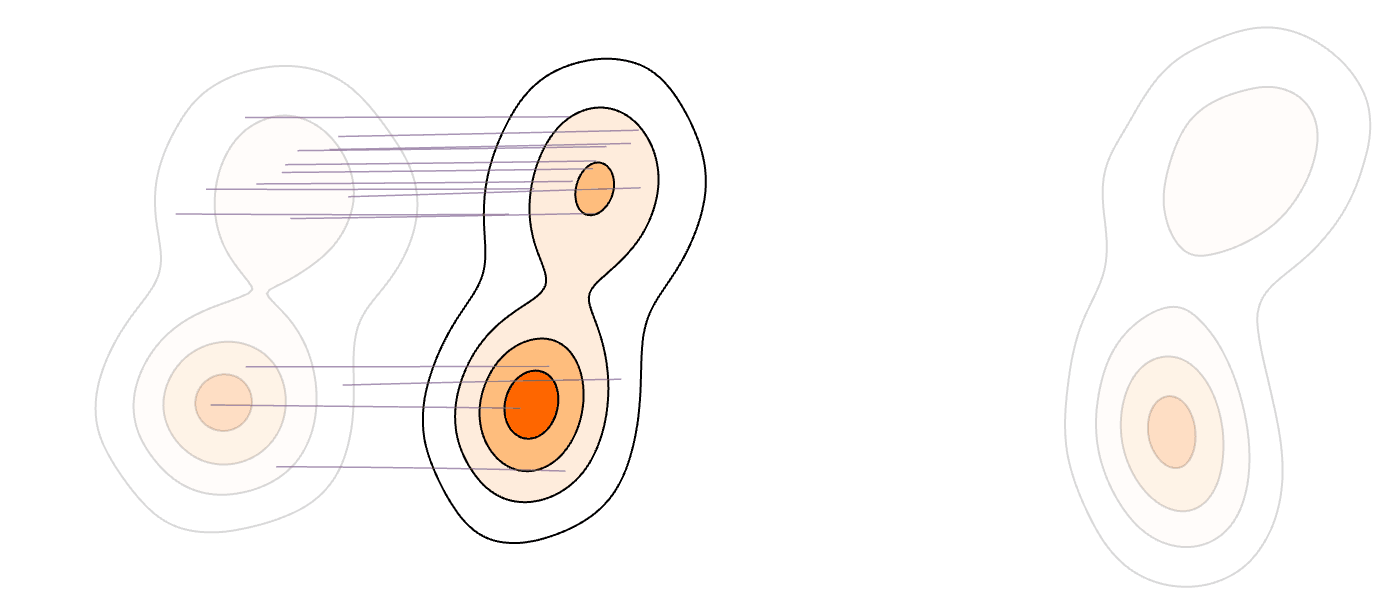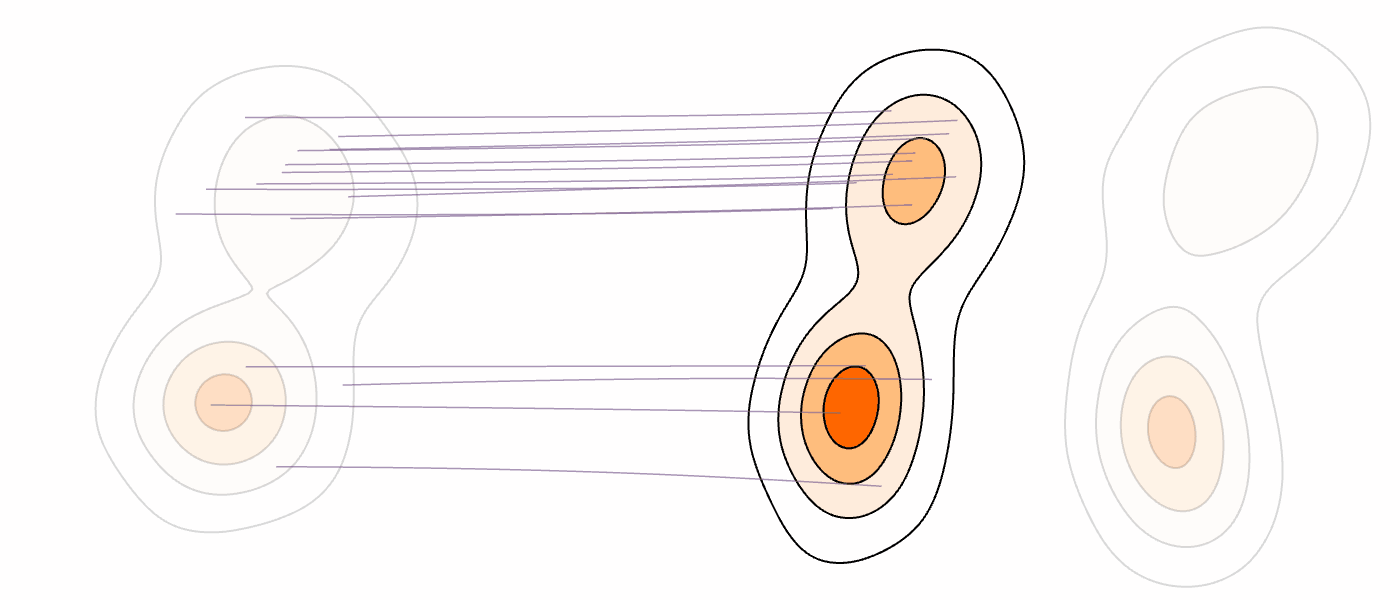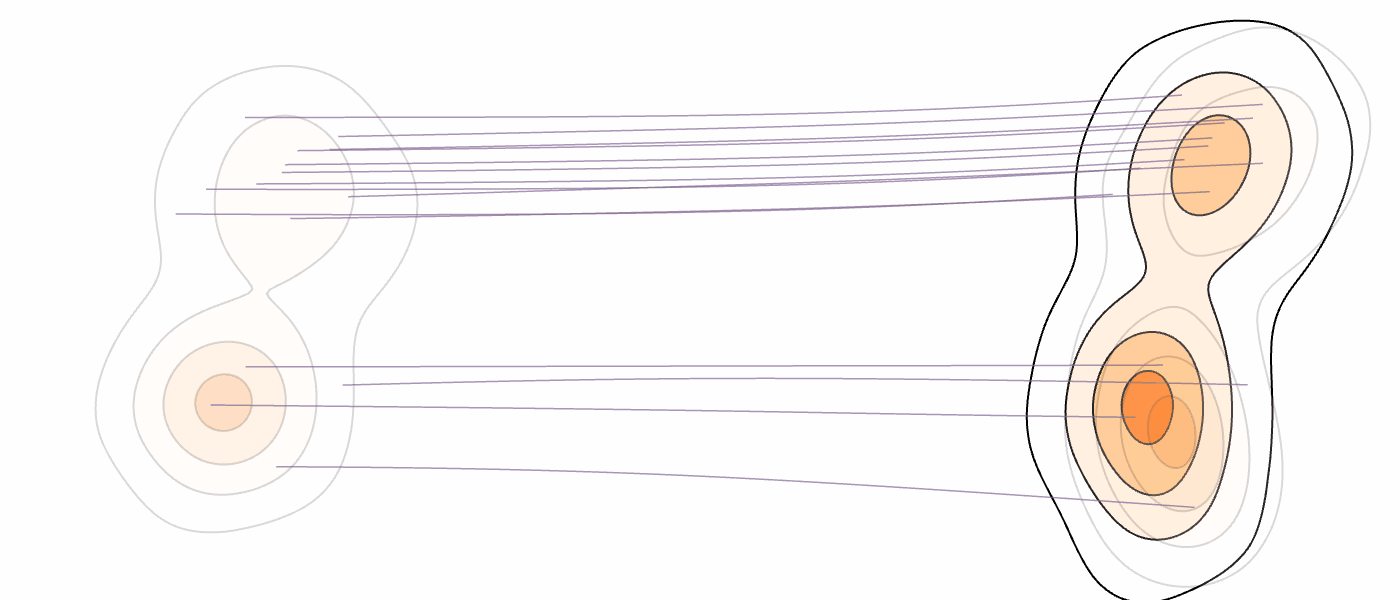
Our Method (MM-FM)
Our algorithm optimizes training efficiency by reducing learning difficulty through three key ideas: (1) employing a vision foundation model (DINOv2-B) as the visual tokenizer to reveal the union-of-manifold structure21 of the data; (2) fitting a GMM to the multimodal target distribution as a warm-start source distribution \(p = \sum_{i=1}^m c_i\mathcal{N}(\mu_i, \Sigma_i)\); and (3) designing a mode coupling \(\pi_{\textrm{mode}}(z_0 \mid z_1)\) that pairs each target sample with a source sample drawn from the nearest GMM mode, enabling local transport of probability mass.
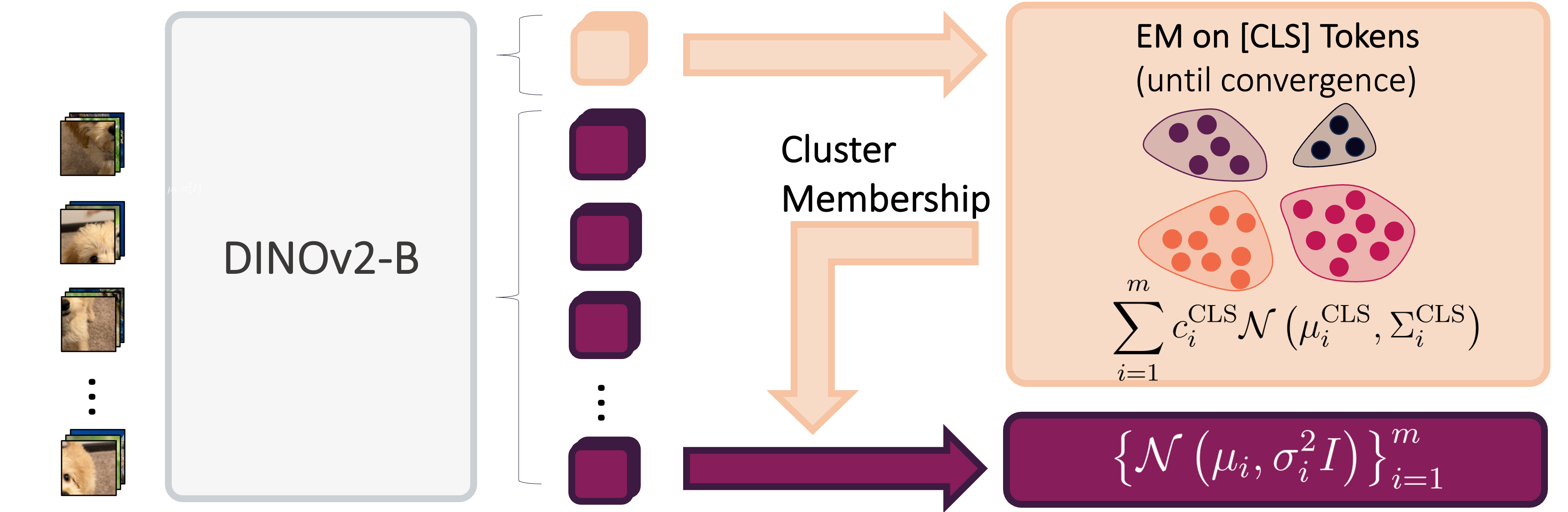
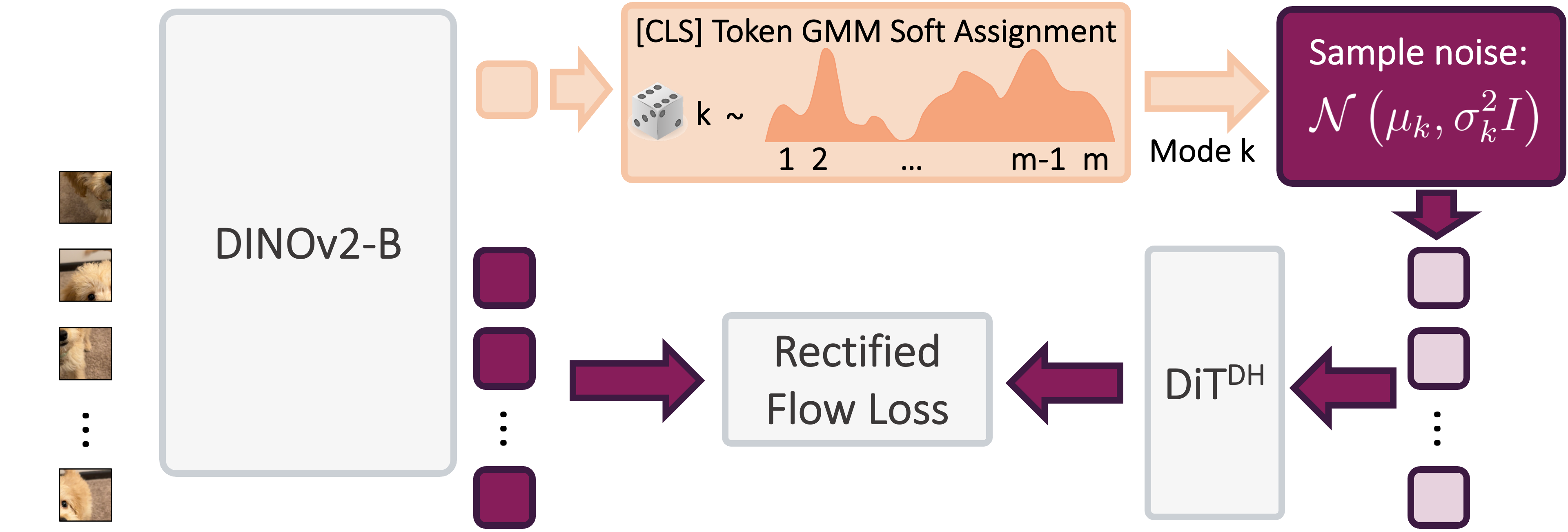
Experimental Results
On ImageNet256 dataset, without any conditioning (i.e., learning a purely unconditional velocity field), MM-FM (FID=3.82) without guidance outperforms the baseline using Gaussian source distribution and independent coupling (FID=9.33) on 80 epochs. It also outperforms the unconditional generation result (FID=4.96) with guidance on 200 epochs reported in RAE2.
Comparing with unconditional generation systems (i.e., without using annotated class labels) without guidance, MM-FM with mode conditioning (FID=3.18) on 80 epochs outperforms DLC16 with DLC conditioning (FID=5.75) on 80 epochs and RCG15 with MoCov3 conditioning (FID=4.89) on 400 epochs.
Though not relying on annotated class labels, MM-FM delivers matching and superior performance comparing with class-conditioning systems (including E2E-VAE11, VA-VAE12, MAETok3, AlignTok13, VFM-VAE14, and SVGTok4) in early checkpoints.
With AutoGuidance17, MM-FM trained for 80 epochs only without using annotated class labels achieves state-of-the-art FID=2.74 generation performance on ImageNet256.
| Method | Tokenizer | Epoch | Params | Prior | Cond. | FID | IS |
|---|---|---|---|---|---|---|---|
| LDM-88 | LDM | 150 | 395M | Gaussian | - | 39.13 | - |
| DiT-XL | SD-VAE | 400 | 675M | Gaussian | - | 27.32 | 35.9 |
| DiT-XL9 | SD-VAE | 80 | 675M | Gaussian | Class | 19.50 | - |
| SiT-XL10 | SD-VAE | 80 | 675M | Gaussian | Class | 17.20 | - |
| SiT-XL | E2E-VAE11 | 80 | 675M | Gaussian | Class | 3.46 | 159.8 |
| LightningDiT-XL | VA-VAE12 | 64 | 675M | Gaussian | Class | 5.14 | 130.2 |
| LightningDiT-XL | MAETok 3 | 64 | 675M | Gaussian | Class | 5.36 | - |
| LightningDiT-XL | AlignTok13 | 64 | 675M | Gaussian | Class | 3.71 | 148.9 |
| LightningDiT-XL | VFM-VAE14 | 80 | 675M | Gaussian | Class | 3.41 | 160.4 |
| SVG-XL | SVGTok 4 | 80 | 675M | Gaussian | Class | 6.57 | 137.9 |
| DiT-XL + RCG15 | SD-VAE | 400 | 738M | Gaussian | MoCov3 | 4.89 | 143.2 |
| DiT-XL + DLC51216 | SD-VAE | 80 | 825M | Gaussian | DLC512 | 5.75 | - |
| DiTDH-XL2 | DINOv2-B | 80 | 839M | GMM | - | 9.33 | 90.6 |
| DiTDH-XL + MM-FM | DINOv2-B | 80 | 839M | GMM | - | 3.82 | 192.3 |
| DiTDH-XL + MM-FM | DINOv2-B | 80 | 839M | GMM | Mode | 3.18 | 211.2 |

Besides training efficiency, MM-FM achieves inference efficiency due to reduced crossing of flows during training time. As a result, it has straighter sampling trajectories and thus requires fewer Euler steps of an ODE sampler. Figure 4 shows that MM-FM requires approximately 5x fewer steps to achieve comparable generation quality relative to Gaussian source distribution with independent coupling.
Ablation Study of GMM Parameters

| FID-50K ↓ | Soft Assignment | Hard Assignment | ||
|---|---|---|---|---|
| Spherical | Diagonal | Full | Diagonal | |
| 11.09 | 10.44 | 10.11 | 10.67 | |
Figure 5 shows MM-FM regardless the # modes perform strictly better than Gaussian with independent coupling. The improvement is monotonic with respect to increasing number of modes toward the degree of reasonable GMM estimation with sufficient data points per mode. Interestingly, the optimal # modes isn't 1000, suggesting that the underlying data manifold contains richer intrinsic structure beyond the categorization provided by annotated labels, which MM-FM can effectively capture. More importantly, class labels are not always available for image datasets. Table 2 shows that the choice of covariance and assignment type only marginally affects the performance relative to the gain by tuning # modes.
Data Efficiency
| FID-50K ↓ | 400 Epochs | 800 Epochs | ||
|---|---|---|---|---|
| Baseline | MM-FM | Baseline | MM-FM | |
| 24.65 | 8.04 | 24.33 | 7.48 | |
We evaluate MM-FM in a data-scarce regime by training on only 10% of ImageNet256 (stratified sampling). Table 3 demonstrates that MM-FM achieves substantially better performance than the baseline with Gaussian source distribution and independent coupling, when both models are trained to convergence (800 epochs).
Our MM-FM lowers the learning difficulty and thus reduces the demand of training data volume. The visual examples for this experiment are in Figure 6.

Ablation Study of Foundation Model Encoders
We ablate the choice of foundation model encoder used for GMM fitting. Table 4 compares DINOv2-B, SigLIP2-B, and MAE-B in terms of linear probing accuracy and downstream generation quality (FID-50K).
| Method | Tokenizer | Probing Acc. ↑ | Epoch | Prior | Cond. | FID ↓ |
|---|---|---|---|---|---|---|
| DiTDH-XL | DINOv2-B | 84.5% | 20 | Gaussian | - | 16.51 |
| DiTDH-XL + MM-FM | DINOv2-B | 84.5% | 20 | GMM | - | 4.95 |
| DiTDH-XL + MM-FM | DINOv2-B | 84.5% | 20 | GMM | Mode | 4.84 |
| DiTDH-XL | SigLIP2-B | 79.1% | 20 | Gaussian | - | 15.21 |
| DiTDH-XL + MM-FM | SigLIP2-B | 79.1% | 20 | GMM | - | 8.27 |
| DiTDH-XL + MM-FM | SigLIP2-B | 79.1% | 20 | GMM | Mode | 7.38 |
| DiTDH-XL | MAE-B | 68.0% | 20 | Gaussian | - | 27.19 |
| DiTDH-XL + MM-FM | MAE-B | 68.0% | 20 | GMM | - | 17.48 |
| DiTDH-XL + MM-FM | MAE-B | 68.0% | 20 | GMM | Mode | 16.40 |
Main Theoretical Results
We analyze multimodal generation with matched mixture distributions:
Here \(\tilde{q}\) and \(\tilde{p}\) are unimodal base distributions (e.g., standard Gaussians), and the mixtures are formed by placing transformed copies at locations \(\mu_k\) with covariances \(\Sigma_k\). Both \(p\) and \(q\) share the same parameters \(\{\mu_k,\Sigma_k\}_{k=1}^{m}\).
We compare two coupling strategies: mode coupling \(\pi_{\text{mode}}\) (our approach, where each source mode \(p_k\) flows only to the corresponding target mode \(q_k\)) vs. independent coupling \(\pi_{\text{ind}}\) (standard approach, where source and target are sampled independently). We measure the complexity of the multimodal generation problem by:
Assumption 1
- The support \(\Omega\) of \(\tilde{p}\) and \(\tilde{q}\) is bounded and convex, and its affine images \(\{\Omega_k\}_{k \in [m]}\) are mutually disjoint. For every pair \(j,k \in [m]\) with \(j \neq k\) and every \(z \in \Omega_k\):
\[ \|z-\mu_k\|_{\Sigma_k^{-1/2}} < \text{dist}_{\Sigma_j^{-1/2}}(z,\Omega_j) \]
- The velocity field \(\tilde{u}_t\) bridging \(\tilde{p}\) and \(\tilde{q}\) is Lipschitz continuous for every \(t \in (0,1)\), and its Jacobian is defined globally in \(\Omega\).
Interpretation: The first item essentially states that the modes \(\{\mu_k\}_{k=1}^m\) are sufficiently well-separated. The second item is a technical assumption on \(\tilde{p}\) and \(\tilde{q}\), commonly satisfied when both \(\tilde{p}\) and \(\tilde{q}\) are smooth, and their ratio \(\frac{\tilde{p}}{\tilde{q}}(x)\) is always nonzero.
Theorem 1
Under Assumption 1, with multimodal prior \(p\) and mode coupling \(\pi_{\text{mode}}\):
- \[ \text{Straightness}(p,q;\pi_{\text{mode}}) \leq C \cdot \text{Straightness}(\tilde{p},\tilde{q};\pi_{\text{ind}}), \] where \(C := \sum_{k=1}^{m} c_k \|\Sigma_k\|_{\text{op}} \leq 1\).
- \[ \text{Length}(p,q;\pi_{\text{mode}}) \leq \left(\sum_{k=1}^{m} c_k \|\Sigma_k\|^{1/2}_{\text{op}}\right) \cdot \text{Length}(\tilde{p},\tilde{q};\pi_{\text{ind}}) \]
- \[ \text{Lip}(u_t) \leq \text{Lip}(\tilde{u}_t), \quad \forall t \in (0,1) \]
Interpretation: When using the multimodal prior and the mode coupling, the straightness, total length, and velocity field Lipschitz constant of the multimodal generation problem never exceed that of the unimodal generation problem.
For additional theoretical results and complete proofs, please refer to our paper.
Conclusion
We propose MM-FM, which leverages vision foundation models as encoders to reveal the union-of-manifold structures in the latent space, and co-designs a multimodal GMM source distribution and mode coupling to exploit these structures. It delivers faster convergence and superior generation performance compared to the classic flow matching recipe that stays on unimodal Gaussian and independent coupling. We wish it provides a principled flow design for the co-evolution of foundation models and generative models. As more foundation models emerge across domains, training flow-based generative models can be made efficient by MM-FM.
For curious readers, we recommend Flow Matching Guide, Rectified Flow Tutorial, and A Visual Introduction to Rectified Flows for flow matching basics. For the insights into structured latents and training efficiency, we also recommend SVG and RAE's project page.
Citation
If you find this work useful, please consider citing:
References
- Esser et al. "Scaling rectified flow transformers for high-resolution image synthesis." ICML'24. [Paper]
- Zheng et al. "Diffusion Transformers with Representation Autoencoders." ICLR'26. [Project Page]
- Chen et al. "Masked Autoencoders Are Effective Tokenizers for Diffusion Models." ICML'25. [Paper]
- Shi et al. "Latent Diffusion Model without Variational Autoencoder." ICLR'26. [Project Page]
- Helbling, et al. "Diffusion Explorer: Interactive Exploration of Diffusion Models." IEEE VIS'25. [Demo]
- Liu et al. "Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow." ICLR'23. [Tutorial]
- Lee et al. "Minimizing trajectory curvature of ode-based generative models." ICML'23. [Paper]
- Rombach et al. "High-Resolution Image Synthesis with Latent Diffusion Models." CVPR'22. [Paper]
- Peebles et al. "Scalable Diffusion Models with Transformers." ICCV'23. [Project Page]
- Ma et al. "SiT: Exploring Flow and Diffusion-based Generative Models with Scalable Interpolant Transformers." ECCV'24. [Project Page]
- Leng et al. "REPA-E: Unlocking VAE for End-to-End Tuning of Latent Diffusion Transformers." ICCV'25. [Project Page]
- Yao et al. "Reconstruction vs. Generation: Taming Optimization Dilemma in Latent Diffusion Models." CVPR'25. [Paper]
- Chen et al. "Aligning Visual Foundation Encoders to Tokenizers for Diffusion Models." arXiv. [Project Page]
- Bi et al. "Vision Foundation Models Can Be Good Tokenizers for Latent Diffusion Models." arXiv. [Paper]
- Li et al. "Return of Unconditional Generation: A Self-supervised Representation Generation Method." NeurIPS'24. [Paper]
- Lavoie et al. "Compositional Discrete Latent Code for High Fidelity, Productive Diffusion Models." NeurIPS'25. [Paper]
- Karras et al. "Guiding a Diffusion Model with a Bad Version of Itself." NeurIPS'24. [Paper]
- Issachar et al. "Designing a Conditional Prior Distribution for Flow-Based Generative Models." arXiv. [Paper]
- Jia et al. "Structured Diffusion Models with Mixture of Gaussians as Prior Distribution." arXiv. [Paper]
- Chen et al. "Gaussian Mixture Flow Matching Models." ICML'25. [Paper]
- Brown et al. "Verifying the Union of Manifolds Hypothesis for Image Data." ICLR'23. [Paper]